
Executive summary
- What: Annex IV of Regulation (EU) 2024/1689 specifies the nine sections every high-risk AI system must produce as its technical file under EU AI Act Article 11. Without a complete, current Annex IV technical file, you cannot lawfully place the system on the EU market.
- Who: Every provider of an Annex III high-risk system — and every annotation, data, or model supplier whose work appears inside that system.
- By when: 2 August 2026. The Commission's December 2025 Digital Omnibus proposal floats pushing this to December 2027, but no provider should treat the extension as binding until ratified.
- Penalty for incomplete Annex IV technical documentation: up to €15 million or 3% of global annual turnover, whichever is higher.
If you supply training data, run an annotation pipeline, or build models for a high-risk AI system going to market in the EU, the EU AI Act Annex IV technical file is the document that decides whether your customer ships on 2 August 2026 or gets pulled from the market. Most public guides cover the nine sections at the surface. This one is written from the angle that matters most for our work at LabelFort: the two sections — Section 2 (development process and data governance) and Section 4 (performance metrics) — that are nearly impossible to reconstruct after the fact, and that decide whether your annotation evidence holds up under a Notified Body Annex IV review.
What is Annex IV?
EU AI Act Article 11 requires every provider of a high-risk AI system (defined in Annex III: biometrics, employment, education, credit scoring, law enforcement, migration, justice, and others) to draw up technical documentation before the system is placed on the market and to keep it current throughout the system's lifecycle. Annex IV is the regulation's exhaustive specification of what that high-risk AI system technical documentation must contain.
The file is not a marketing artefact. It is the evidentiary backbone of your CE-mark conformity assessment — the package your Notified Body reads to decide whether your system meets the requirements of Chapter III, Section 2 of Regulation (EU) 2024/1689. Get it wrong and the system cannot ship in the EU. Get it incomplete and you remain exposed to the €15M / 3% fine for the lifetime of the product.
The 9 sections of an Annex IV technical file
The structure is fixed. Notified Bodies expect to read it in this order, with these names, and find each section either populated or with a defensible reason for its absence.

Section 1 — General description
A plain-language description of the AI system, including: intended purpose, the name and contact of the provider, version, the system's interactions with hardware or other software, software versions, user interface designs, instructions for use, and a description of the hardware on which the system is intended to run.
This is where most providers under-deliver. "Intended purpose" is the legal anchor for every downstream Article 9 risk management system step and every Article 14 human oversight measure. A vague "the system supports loan officers in credit decisions" will fail. A precise "the system produces a probability-of-default score on consumer loan applications in retail banking, used to rank applications shown to a human underwriter, who retains final decision authority" will pass.
Section 2 — Detailed description of elements and development process
This is the section that catches annotation providers out, and the operative clause for AI Act Article 11(2)(b) data governance. It must cover:
- The methods and techniques used to develop the AI system, including any pre-trained systems used.
- The design specifications — the general logic of the system, key design choices, and assumptions.
- The system architecture — how software components build on or feed into each other.
- The data requirements — datasheets for datasets (the Gebru pattern is the de-facto template) describing the training methodologies and the training, validation, and testing data sets, including a general description, data provenance, scope and main characteristics, how the data was obtained and selected, labelling procedures, and data cleaning methodologies. This is the sub-clause that lives or dies on what your annotation provider can produce as evidence-grade data annotation EU AI Act auditors will accept.
- The human oversight measures designed in under Article 14.
- The pre-determined changes the system is allowed to make to itself.
- The validation and testing procedures used — including metrics, test data composition, and test logs.
- The cybersecurity measures put in place under Article 15.
Section 3 — Monitoring, functioning, control
Detailed information about the monitoring, functioning, and control of the AI system, including: capabilities and limitations in performance, degrees of accuracy for specific persons or groups, foreseeable unintended outcomes and sources of risks to health, safety, fundamental rights, and discrimination, and the human oversight measures needed.
The "specific persons or groups" requirement is what turns Section 3 into a fairness-evidence section. You cannot meet it with a single aggregate accuracy figure — cohort stratification is implicit here and explicit in Section 4.
Section 4 — Performance metrics justification
A description of the appropriateness of the performance metrics used. Why F1? Why AUC? Why a precision floor of 0.92? The regulation does not prescribe metrics — under AI Act Article 11(2)(d) performance metrics, the provider must justify the choice in writing. This section also requires per-cohort performance metrics — accuracy broken down by every relevant cohort surfaced in Section 3.
Section 5 — Risk management system
A description of the Article 9 risk management system — identification, analysis, evaluation, and mitigation of foreseeable risks to health, safety, or fundamental rights, across both intended use and reasonably foreseeable misuse. Article 9 is iterative: the risk management system is a continuous process, not a one-off document. Section 5 must show the loop.
Section 6 — Lifecycle changes
Description of relevant changes made by the provider to the system through its lifecycle: model retraining, threshold adjustments, new data ingestion, and any change that could materially affect performance, fairness, or safety. Each substantive change re-opens the conformity assessment — Section 6 is the evidence trail.
Section 7 — Harmonised standards
A list of harmonised standards applied in full or in part. Where no harmonised standard is applied, a description of the solutions adopted to meet the requirements. CEN-CENELEC JTC 21 is the body publishing the harmonised standards under the AI Act. ISO/IEC 42001 (AI management systems) is the complementary anchor for the management-system side of compliance, alongside Article 10 data quality obligations.
Section 8 — Copy of the EU Declaration of Conformity
A signed copy of the EU Declaration of Conformity required under Article 47. The legal instrument by which the provider takes responsibility for the conformity of the system. The Declaration references the Annex IV file by version and hash — keep the linkage tight.
Section 9 — Post-market monitoring plan
A detailed description of the post-market monitoring plan put in place under Article 72 — what is monitored, how, by whom, at what cadence, and how findings feed back into the risk management system (Section 5) and lifecycle changes (Section 6).
The LabelFort wedge — why Section 2 is impossible to reconstruct after the fact
Every Annex IV section needs evidence. Most can be produced retroactively. Section 2 is different.
Section 2 requires evidence of decisions you made and procedures you ran at the moment data was labelled. Specifically, you must produce:
| Sub-clause | Evidence the audit will ask for |
|---|---|
| Provenance of the data set | Source records — where the data came from, lawful basis for processing, transfer log if cross-border, deduplication evidence. |
| Selection criteria | The inclusion/exclusion rules you applied at sourcing, with reasons. "We excluded images with patient identifiers visible" is fine if you can show the rule was applied. |
| Labelling procedures | The exact instruction set used, version history of that guideline, the qualification of the labellers, how disagreements were resolved, and the inter-rater reliability metric (Cohen's kappa or Krippendorff's α) the procedure produced. |
| Data cleaning methodologies | The outlier-detection logic, the de-duplication logic, the rule for handling missing values, and a sample log of cleaned records. |
| Datasheet | A single document — Gebru-pattern datasheet for datasets — that pulls all of the above into a per-dataset record. |
None of these can be honestly reconstructed two months after the data has been shipped. The annotator's screen state, the inter-rater reliability between Annotator A and Annotator B on disputed records, the version of the guideline at the moment a particular record was labelled — these decay irrecoverably the moment the annotation tool moves to the next batch.
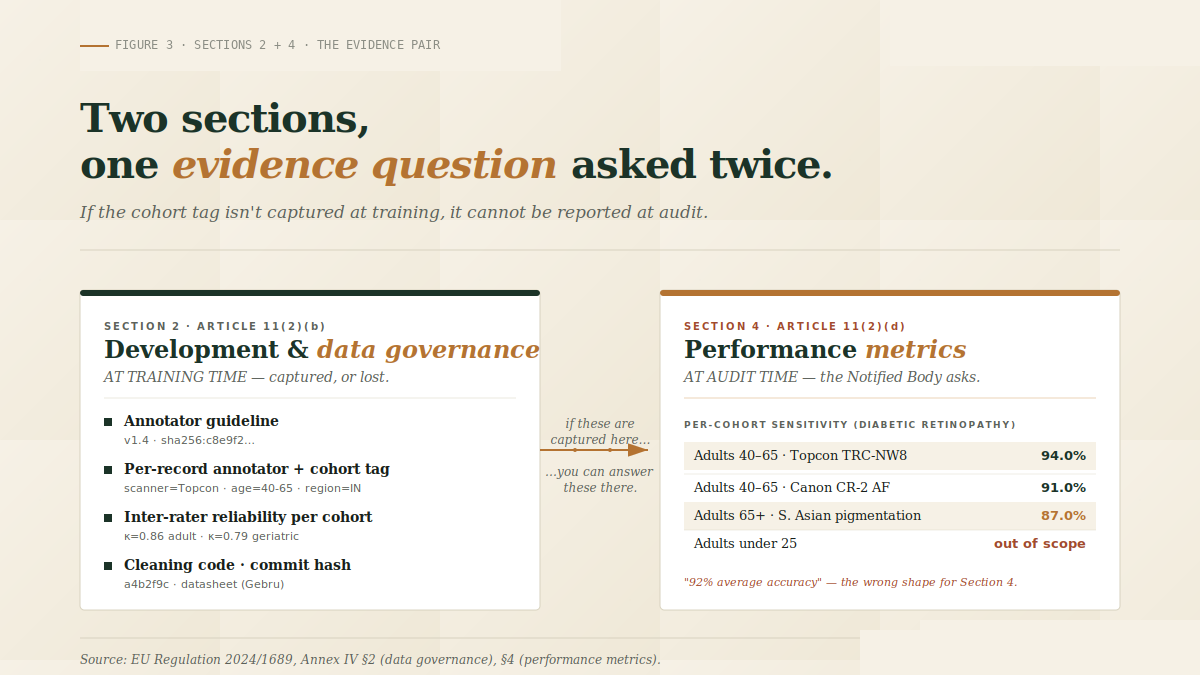
This is the design constraint that defines what we mean at LabelFort by evidence-grade annotation: every artefact that Annex IV Section 2 will ask for is captured at the time of annotation, versioned, and exportable as a single per-dataset AI Act audit evidence bundle — not promised after the fact.
In practice, that bundle contains:
- The signed annotator guideline, with version hash, applicable to every record in the batch.
- Per-record annotator identity, qualification record, and time-stamp.
- Per-record disagreement log between primary and secondary annotator, with the adjudication decision.
- Cohort-level inter-rater reliability (Cohen's κ or Krippendorff's α) broken down by the cohorts the model's Section 3 will need to evidence.
- The cleaning rule set, applied as code with a commit hash, and a sample of cleaned vs uncleaned records.
- The datasheet — Gebru-pattern — auto-populated from the underlying log rather than written from memory.

Section 2 does not become easy because of this. It becomes possible. That is the difference our customers buy.
Section 4 — and why "average accuracy" is a fail mode
Section 4 asks you to justify your performance metrics and present performance broken down by relevant cohort. For a medical-imaging AI screening for diabetic retinopathy, "92% sensitivity" is not Section 4 evidence. The auditable form is:
- 94% sensitivity on adults aged 40–65, captured on Topcon TRC-NW8 scanners.
- 91% sensitivity on adults aged 40–65, captured on Canon CR-2 AF scanners.
- 87% sensitivity on adults aged 65+, with sub-cohorts for South Asian and East African retinal pigmentation profiles.
- Sensitivity below 80% on adults under 25 — flagged as out-of-scope, with the exclusion documented in Section 1.
You cannot generate that table at audit time. You can only generate it if your training annotation captured the cohort tags. This is why Sections 2 and 4 are an evidence pair, and why per-cohort performance metrics under the EU AI Act stand or fall on the discipline of the upstream annotation workflow.
A worked example — Annex IV for a high-risk medical imaging system
| Section | Evidence the file contains (illustrative) |
|---|---|
| 1. General description | Diabetic retinopathy triage AI; intended purpose; provider details; v3.2.1; deployed on hospital PACS; HL7 FHIR integration; user manual v3.2.1. |
| 2. Development & data governance | Dataset card v3 covering 47,000 retinal scans across 3 sites; provenance log including cross-border transfer record (India → EU under standard contractual clauses); annotator guideline v1.4; 6 ophthalmologist labellers credentialed; per-cohort IRR (κ = 0.86 adult, 0.79 geriatric — flagged for re-review); cleaning code at commit a4b2f9c. |
| 3. Monitoring & control | Capability statement; per-cohort accuracy table; foreseeable misuse register; Article 14 human oversight design. |
| 4. Performance metrics | Sensitivity 91.2%, specificity 94.6%, AUROC 0.96; cohort breakdown; metric justification. |
| 5. Risk management | Article 9 risk register v3; harm identification matrix; mitigation log; residual risk acceptance signed by the medical director. |
| 6. Lifecycle changes | Three retrainings since first launch; one threshold change after post-market monitoring flagged geriatric drift. |
| 7. Harmonised standards | ISO/IEC 42001:2023 management system; no harmonised standard on bias measurement, so Article 10 data quality evidence presented under documented alternative. |
| 8. Declaration of Conformity | Signed by CEO; referenced to Annex IV file hash. |
| 9. Post-market monitoring plan | Quarterly accuracy audit on production data; complaint log; serious incident reporting per Article 73. |
What about the Digital Omnibus extension?
In December 2025 the Commission proposed pushing the Annex III high-risk obligations to December 2027 in its "Digital Omnibus" simplification package. As of May 2026 the proposal is in the legislative pipeline; nothing is final. Three rules of thumb:
- Plan to ship for 2 August 2026. If the extension lands, you have a buffer; if it doesn't, you are not caught.
- Don't slow down your annotation discipline. Section 2 evidence of quality decays with delay, not with deadline.
- Watch the Council position. Treat any "the deadline moved" headline with the scepticism you would apply to any draft regulation.

The 9-section ready-to-export Annex IV checklist
Copy the table, RAG-status each row, and the gap-list is your next 60 days of compliance work.
| Section | Produced? | Versioned? | Survives Notified Body spot-check? |
|---|---|---|---|
| 1. General description | |||
| 2. Development & data governance | |||
| — Datasheet (Gebru-pattern) | |||
| — Annotator guideline (versioned) | |||
| — Inter-rater reliability per cohort | |||
| — Data cleaning code + commit hash | |||
| — Provenance log incl. cross-border | |||
| 3. Monitoring & control | |||
| 4. Performance metrics (cohort breakdown) | |||
| 5. Risk management (Article 9) | |||
| 6. Lifecycle changes log | |||
| 7. Harmonised standards applied | |||
| 8. Declaration of Conformity (Article 47) | |||
| 9. Post-market monitoring plan (Article 72) |
Compliance posture
Five frameworks. One annotation backbone that passes Legal, Security, and Procurement.
FAQ
Q. When does Annex IV apply to my AI system?
Annex IV applies if your system is classified as high-risk under Annex III of the EU AI Act. It must be produced before placing the system on the EU market or putting it into service in the EU, and kept current for the life of the system. The high-risk Annex IV obligations apply from 2 August 2026 under the Article 113 timetable.
Q. What's the penalty for an incomplete or missing Annex IV technical file?
Up to €15 million or 3% of total worldwide annual turnover, whichever is higher, for non-compliance with Article 11.
Q. Does Annex IV apply to SMEs and startups?
Yes. Article 11(1) permits SMEs and startups to supply the Annex IV elements in a simplified manner — the Commission was directed to publish a simplified form. As of Q2 2026 that form has not yet been published, so SMEs should produce the full Annex IV structure.
Q. Can annotation be done in-house and still meet Annex IV Section 2 evidence requirements?
Yes. The regulation is agnostic on whether annotation is in-house or outsourced. What it requires is the evidence — provenance, procedure, inter-rater reliability, cleaning, and datasheet.
Q. What's the link between Annex IV and ISO/IEC 42001?
ISO/IEC 42001 is the international management-system standard for AI. It is complementary to Annex IV: 42001 evidences the management system; Annex IV evidences the technical file for a specific system.
Q. How does LabelFort produce Section 2-ready evidence?
Every batch processed through our evidence-grade workflow ships with a versioned annotator guideline, per-record annotator and adjudicator identity, cohort-level inter-rater reliability, cleaning code with commit hash, and a Gebru-pattern datasheet — exportable as a single per-dataset bundle.
Q. What's the relationship between Annex IV and General-Purpose AI (GPAI) provider obligations?
Separate. GPAI providers have their own obligations under Articles 53–55. Annex IV is the high-risk-system technical file; GPAI obligations are the foundation-model-provider obligations. A single organisation can be both.
Q. Is Annex IV needed for limited-risk or minimal-risk systems?
No — Annex IV is the high-risk technical-file standard. Limited-risk systems have transparency obligations under Article 50 but no Annex IV file.
Q. How often must Annex IV be updated?
Continuously. Article 11 requires the technical documentation to be kept up to date. Material changes to the system, the data, or the risk profile reopen the relevant sections — most often Sections 2, 4, 6, and 9.
Next step
Ready to evaluate your Annex IV evidence against a Notified Body's checklist?
We help AI providers prepare Annex IV-grade evidence for the annotation and data governance sections of their technical file, before the file ever reaches a Notified Body. Start with a Compliance Review — a one-hour structured walkthrough of your current state and the gap to audit-ready. From there, an evidence-grade PoC proves the workflow on a real batch in two weeks.